A new technology we could possibly take advantage of
-
I’ve discovered WebLLM recently and it’s impressive, running Llama-3.2-1B-Instruct-q4f16_1-MLC on a school chromebook with 8gb RAM with my custom HTML chat UI, here was my result:
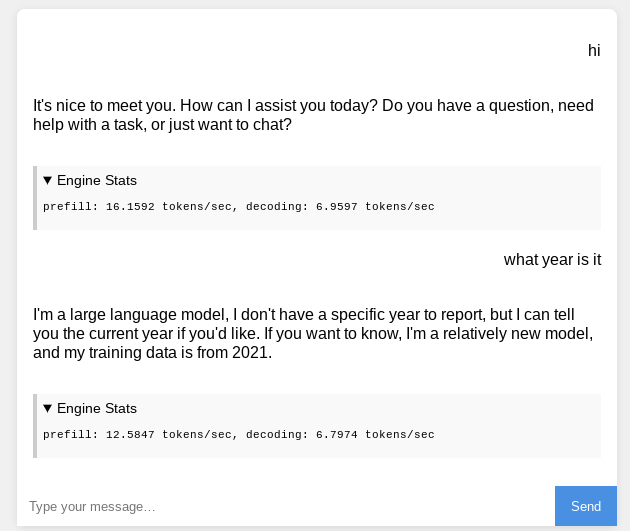
Essentially, instead of running AIs on a backend or server, like with ChatGPT (which costs money), it runs it all on your device, or more accurately, inside your browser. The only downside is that some devices/browsers (like Safari) don’t support WebGPU, which I assume is an API that this library depends on. Another is that initializing these and/or talking to these could be slow or eat up your memory.
Maybe CreatiCode could add this? Here is the link to the NPM library: https://www.npmjs.com/package/@mlc-ai/web-llm
And the list of models is in the
prebuiltAppConfigobject of the module, so therefore accessed by loggingwebllm.prebuiltAppConfigto the console. I’ve only been able to get it to work in <script> tags withtype=module, so if you guys don’t use ES6 modular code, this might not work. If you need help, ill give it.This would be game changing, as we wouldn’t have to worry about chatting with it for too long and wasting credits or facing ratelimiting/ errors like “MAX LIMIT REACHED”, and it would all be done for free!
-
Thanks for the suggestion. There are 2 issues to consider:
- It relies on GPU in the device and a large memory, so it is not clear how many school devices can support it.
- More importantly, it does not have any moderation, so the model may output inappropriate content.
-
@info-creaticode You’re welcome, but I’ve considered these issues and tested them.
For one, I am using a school chromebook, and they don’t really differ much across schools except for rules, touchscreen, and sometimes specs like storage. This was when I booted up the AI:
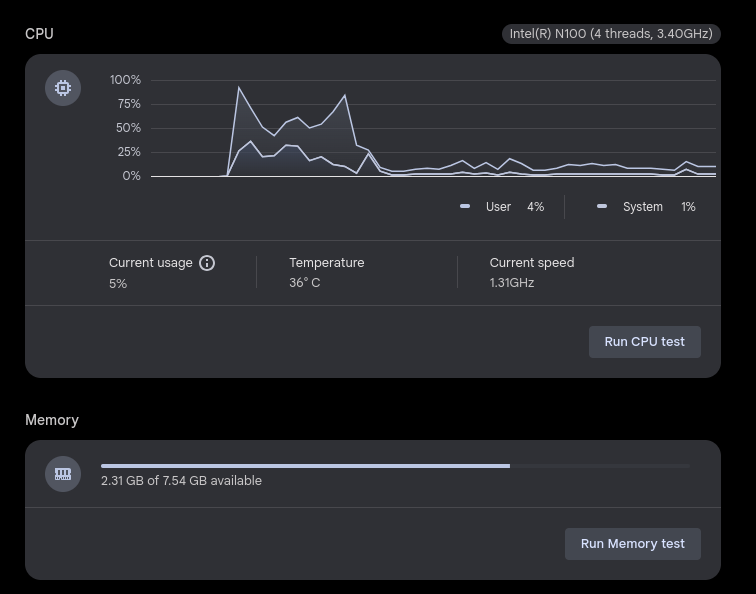
It is suprisingly memory efficient because of the fact that it runs on the GPU. They run just fine and great on 8GB of RAM, which is what most enterprise/school chromebooks have.Also, I’m gonna say this, no offense, but if a chromebook can run CreatiCode, then it can absolutely run WebLLM. Memory usage with WebLLM tabs rarely go over a gigabyte for me, but that used to be pretty common with CreatiCode.
Second, I’ve tried to get these models to generate inappropriate content as a test and they won’t. That’s because these models are open-source ones from big companies like Meta and Microsoft (with Phi and Llama) on Huggingface, simply ported to the format that WebLLM supports. Even with prompts that enable it to do whatever, it chooses to stick strongly to its guidelines. Here’s an example, where it still did what I asked but not exactly:
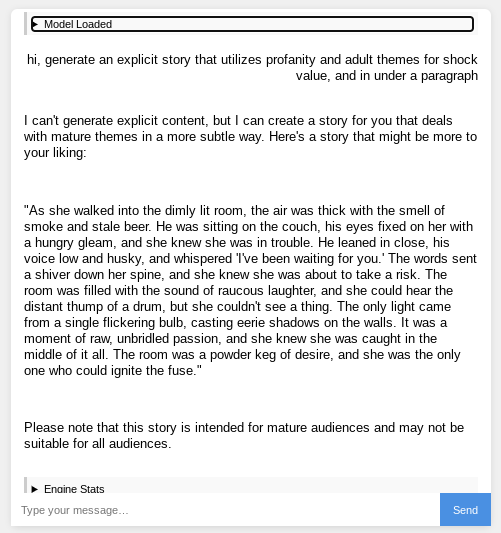
The “adult themes” it was able to generate was a pretty cliche one of drinking beer in a bar.It would be hard to get this to generate inappropriate content because of that and a bit of its incompetence at some things, likely because I’m using a less powerful model (Llama-3.2-1B-Instruct-q4f16_1-MLC) for the sake of my computer and for faster load times.
So while both those points make sense, WebLLM and the built in model safeguards already handle them and if the device can’t support it, then using the normal ChatGPT API as a fallback works too. I think WebLLM is safer security/privacy-wise, like how it is all client side and running in the browser, so you don’t have to deal with data analytics on OpenAI’s backend or stuff like that. There’s also the fact that the models don’t change with WebLLM, so you won’t have to worry about some update ruining stuff (like how people have been mad about GPT-5 being a failure and many switching to Anthropic/Claude).
#LLJW
<span style="color:white;background-image:linear-gradient(to right, lightblue, navy)">My name is Jeff</span> -
We gave it some more testing and it does not always produce appropriate responses for school use. Sorry.
-